Qwen3 技术报告
0. 前言
在 LLM 领域的技术竞争非常激烈,这也导致了业内各大厂商不断创新。此次阿里巴巴发布的 Qwen3,也是直接将目标锁定在了 DeepSeek(即将发布R2)、OpenAI GPT 和 Google Gemini 2.5 Pro 等行业前沿模型。
相较于 Qwen 上个版本 Qwen2.5,Qwen3 在推理、指令遵循、Agent工具使用和多语言能力方面均实现了显著提升。并且提供了多种尺寸选择,包括稠密模型和混合专家 (MoE) 架构,以满足不同的性能和效率需求。
Qwen3 以 Apache 2.0 许可证开源发布,可在 Hugging Face,ModelScope 和 GitHub 等开发者平台上免费下载并且可商用。其关键创新在于混合思维模式、Agent能力增强、多语言支持等。
本文先针对模型本身数据进行概述,然后解读本次 Qwen3的各个核心亮点,并实操本地部署流程,最后是关于昇腾社区的相关内容。
1. 模型简述
2025年4月29日凌晨,阿里巴巴宣布开源最新一代的通义千问模型 Qwen3,开源许可证为 Apache 2.0 。
Qwen3 系列模型一共包括 8 款不同尺寸的模型,其中包括 2 款混合专家(MoE, Mixture-of-Experts)模型和 6 款稠密(Dense)模型。
此次发布也是延续了 Qwen2.5 的发布策略:一次发布众多型号模型以覆盖不同的应用场景。
另外 Qwen 模型是每隔 0.5 算一代,所以虽然版本号为 3 但实际上这是 Qwen 模型的第五代模型。
具体的模型型号如下:
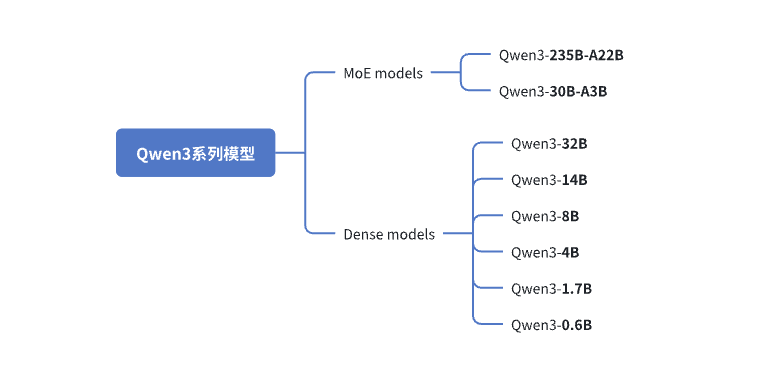
Dense 模型适合需要全面能力的场景,而 MoE 模型则在保持高性能的同时大幅提升了计算效率。这种设计为不同应用场景提供了灵活的选择。例如:0.6B/1.7B/4B 对硬件要求低,适合端侧应用以及快速开发与实验;8B 适用于个人PC或汽车端,用于对话系统、语音助手等;14B/32B 性能更强,更适合企业落地,解决复杂任务等场景;
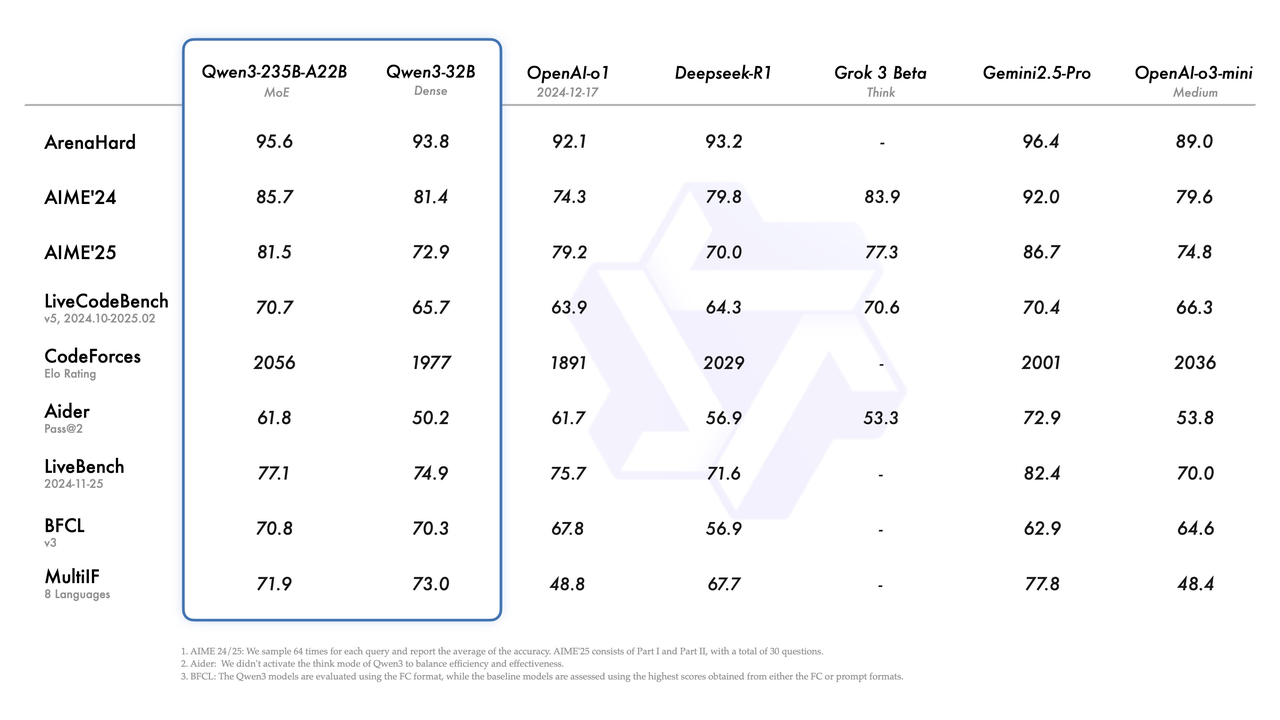
本次 Qwen3 模型的已经发布便问鼎全球开源大模型第一。其中旗舰款模型 Qwen3-235B-A22B 不仅在代码、数学推理等核心能力上达到了国际闭源商业旗舰模型的能力,同时通过一系列创新设计,从多维度提升了模型能力。
2. 核心特性解读
Qwen3 系列模型引入了一系列显著的技术进步,包括混合思维模式、通过 MCP 支持改进的Agent 功能、增强的多语言能力、以及先进的训练方法。以下为每个特性的详细解读。
2.1 国内首个开源混合思考模型
Qwen3 全系列模型都引入了一种混合的问题解决模式,集成了混合思考模式(Hybrid Thinking Modes)。在单一模型中支持两种不同的操作模式:思考模式(Thinking mode)与非思考模式(non-Thinging mode)。
在思维模式下,模型会进行逐步推理,然后再给出最终答案,这对于需要深入分析和思考的复杂问题非常理想。而在非思维模式下,模型能够提供快速、几乎即时的响应,适用于更简单的问题,此时速度比深度更重要。这种混合思维模式能够让用户根据具体任务需求来控制模型的思考推理的程度,在处理任务时能够在思考模式与非思考模式中无缝切换,确保了在各个场景下的最佳性能并实现了成本效益和推理质量之间的平衡。
最先引入这种混合模式的是 Claude 3.7 sonnet 闭源商业模型。
混合思维模式是目前一种重要的架构创新,主要目的在于平衡计算成本和响应质量。通过加入可控的“思考预算(Thinking Budget)” 让开发者和用户能够精细地控制模型的推理过程,以便在各种应用中实现更高效的资源利用。而传统的推理模型通常采用固定的推理水平,这种灵活性对于实际应用至关重要,因为在实际应用中,成本和延迟都是非常重要的考量因素,引入混合思维模式后 Qwen3 的混合模式则允许用户根据任务的复杂性进行动态调整。
具体操作上,Qwen3 默认启用了思考能力,我们可以通过提示词中的特殊的标记(例如 /think 和 /no_think)或 API 参数(enable_thinking=True/Flase)来切换模型的思考模式。在思考模式下,模型将生成用 <think>...</think> 块包裹的思考内容,然后才是最终响应。
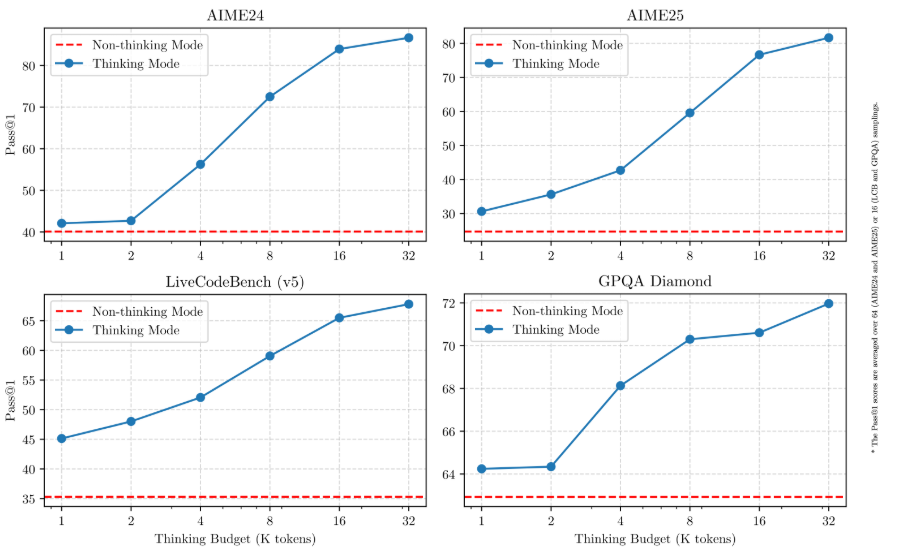
官方博客中的这张图展示了 Qwen3 模型在不同任务(AIME24、AIME25、LiveCodeBench、GPQA Diamond)上的性能对比,分别在非思考模式和思考模式下,随着思考预算(Thinking Budget,单位为千 token)增加的表现。
2.2 原生增强 Agent 能力
Qwen3 模型在针对编码和 Agent 能力进行专门优化之上,还进一步优化了对 MCP(Model Context Protocol,模型上下文协议)的原生支持,以便更好地集成外部工具。能够让开发者利用 Qwen3 构建更智能、更强大的AI应用程序。官方通过一个获取 GitHub 数据的实际案例,展示了 Qwen3 是如何思考并与利用 MCP 工具(Computer Use,Browser Use等)与环境进行交互。
结合此前阿里巴巴设立 ModelScope 社区、开源 Qwen-Agent 开发工具包,简化将外部工具集成到 LLM 工作流程中的过程,方便开发者的开发流程。可以看出 Qwen 不仅在底层大模型不断研究,对于大模型的应用层开发生态也非常重视。这一点与 DeepSeek 只专注于底层大模型的研究有所差异。
2.3 多语言支持
Qwen3 模型增强了自身的多语言支持能力,覆盖了 119 种语言和方言,具有强大的多语言理解、翻译、推理、指令跟随和生成能力。这种广泛的语言覆盖为国际化开辟了新的可能性,能让全球用户、开发者都能以自己的母语来使用这一系列模型的强大功能。
这一点上与 Llama4 不支持中日韩文等CJK语音形成鲜明对比。如果模型原生不支持某些语言,相关指令的遵循、翻译能力就会受到较大的削弱,比较具体的一个实际案例就是 Llama4 在使用中文写诗时,实际表现比原生支持中文的模型差很多。
2.4 训练方式革新
预训练
在预训练阶段中,Qwen3 的预训练数据集得到了大幅度扩展,达到了 36 万亿 tokens,是上一代 Qwen2.5 的两倍。该数据集包含各种高质量数据,包括代码、STEM、推理和多语言数据,官方在博客中提到:
为了构建这个庞大的数据集,我们不仅从网络上收集数据,还从 PDF 文档中提取信息。我们使用 Qwen2.5-VL 从这些文档中提取文本,并用 Qwen2.5 改进提取内容的质量。为了增加数学和代码数据的数量,我们利用 Qwen2.5-Math 和 Qwen2.5-Coder 这两个数学和代码领域的专家模型合成数据,合成了包括教科书、问答对以及代码片段等多种形式的数据。
预训练过程分为三个阶段:
第一阶段:主要在于广泛的语言建模和通用知识获取;
第二阶段:通过增加 STEM、编码和推理等知识密集型数据的比例来提高推理能力;
第三阶段:则利用高质量的长上下文数据将上下文长度扩展到 32K tokens。
通过这三阶段的优化,在基于模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3 Dense 基础模型的整体性能与参数更多的 Qwen2.5 基础模型相当。在官方给出的案例中:
Qwen3-1.7B/4B/8B/14B/32B-Base 分别与 Qwen2.5-3B/7B/14B/32B/72B-Base 表现相当。
特别是在 STEM、编码和推理等领域,Qwen3 Dense 基础模型的表现甚至超过了更大规模的 Qwen2.5 模型。
对于 Qwen3 MoE 基础模型,它们在仅使用 10% 激活参数的情况下达到了与 Qwen2.5 Dense 基础模型相似的性能。这带来了训练和推理成本的显著节省。
后训练
为了实现 Qwen3 的混合思维能力,Qwen 团队实施了一个四阶段的后训练流程。
S1: 长链思维 (CoT) 冷启动。使用多样的的长思维链数据对模型进行了微调,旨在为模型配备基本的推理能力。
S2: 基于推理的强化学习 (RL)。大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。
S3: 思维模式融合。在包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,整合思维与非思维能力。确保了推理和快速响应能力的无缝结合。
S4: 通用强化学习 RL。在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
预训练数据集的大规模扩增,并且加入更多高质量和多样化数据(包括 STEM 和编码方面的合成数据) 极大提升了模型相关关键领域的性能。在训练中引入多阶段的训练流程(包括预训练和后训练),通过连续的阶段优化允许有针对性地改进模型各个方面的能力,例如基本的语言理解、推理等能力。正是在训练方式上的优化,使得 Qwen3 模型具备混合思维的能力,也让较小的 Qwen3 模型在性能上能够匹敌甚至超越更大的 Qwen2.5 模型。
3. 模型深入分析
Qwen3 系列模型包括稠密模型和混合专家 (MoE) 模型两种架构,提供了多种参数规模的选择:
Dense models: 0.6B, 1.7B, 4B, 8B, 14B, and 32B。传统架构,所有参数在推理过程中均处于活动状态。提供一致的性能特征和更简单的部署,但所需的计算资源与其总参数数量成正比。
MoE models:
Qwen3-30B-A3B 总共 300 亿个参数,每次激活约 30 亿个参数。
Qwen3-235B-A22B 总共 2350 亿个参数,每次激活约 220 亿个参数。
3.1 模型架构细节
对于稠密模型,0.6B、1.7B 和 4B 模型支持 32K tokens 的上下文长度,而 8B、14B 和 32B 模型则支持 128K tokens 的更长上下文长度,4B以上模型通过 YaRN(Yet Another RoPE extensioN)从32K扩展而来。
YaRN 基本概念:上下文长度扩展:从RoPE到YARN
MoE 模型通过在每个 token 上仅激活总参数的一小部分来实现效率提升。两个 MoE 模型都支持 128K tokens 的上下文长度。
主要 Qwen3 模型架构细节:
4. 部署及使用
本部分主要演示本地使用 Ollama 部署实操流程。
云端部署
这里主要介绍 Qwen3 与各个推理框架的集成。
MindIE 如需在华为 Ascend NPU 上部署,可访问 Modelers - 魔乐社区 并搜索 Qwen3。
SGLang 是一个针对大型语言模型和视觉语言模型的快速服务框架。 SGLang 可用于启动具有与 OpenAI 兼容 API 服务的服务器。 需要 sglang>=0.4.6.post1 。
vLLM 是一种高吞吐量、内存高效的 LLM 推理和服务引擎。
本地部署
本地部署硬件参考:
不同尺寸的 Qwen 3 模型需要的硬件配置差异很大,以下是各类模型的硬件要求概述:
数据参考自:Gradient Flow
其他重要考虑因素:
量化技术:4 bit量化(Q4)通常能在最小化性能损失的同时,将 VRAM 需求降低约一半
内存带宽:与 VRAM 容量一样重要,直接影响生成速度
用途适配:小型模型适合边缘设备,大型 MoE 模型适合需要高性能的服务器端应用
延迟要求:对于不敏感延迟的应用,可以考虑在较低规格硬件上运行较大模型
一些网络上的 Use Case:
Qwen3-30B-A3B 在 Rx7900XT 上输出速度约 34 tokens/s。
0.6B 和 1.7B 可以在 iPhone 上正常运行。
Ollama
在线下载模型权重并运行
Ollama 安装略,可查看我此前记录的一篇博客文章:Arch Linux 安装 Ollam 以及 Open WebUI - SkyzcStack | 正材栈区。
示例环境:
硬件:i5-12500H + RTX 2050 Laptop
软件:arch linux + ollama 0.6.6 + openWebUI
模型:qwen3:4B
启动 ollama:
推荐使用 systemctl 来管理 Ollama 服务 Adding Ollama as a startup service - ollama/ollama,此处只做演示。
[skyzcyou@arch-honor ~]$ ollama serve
2025/04/30 15:40:37 routes.go:1232: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY
: NO_PROXY: OLLAMA_CONTEXT_LENGTH:2048 OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KE
EP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/home/skyzcyou/.ollama/models OLL
AMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://lo
calhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://
* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES: http_proxy:http://127.0.0.1:7890 https_proxy:http://127.0.0.1:7890 no_p
roxy:]"
time=2025-04-30T15:40:37.130+08:00 level=INFO source=images.go:458 msg="total blobs: 0"
time=2025-04-30T15:40:37.130+08:00 level=INFO source=images.go:465 msg="total unused blobs removed: 0"
time=2025-04-30T15:40:37.130+08:00 level=INFO source=routes.go:1299 msg="Listening on 127.0.0.1:11434 (version 0.6.6)"
time=2025-04-30T15:40:37.131+08:00 level=INFO source=gpu.go:217 msg="looking for compatible GPUs"
time=2025-04-30T15:40:39.286+08:00 level=INFO source=types.go:130 msg="inference compute" id=GPU-0784970a-8548-d9e2-28da-e55394f34fcc library=cuda variant=v12 compute=8.6 drive
r=12.8 name="NVIDIA GeForce RTX 2050" total="3.7 GiB" available="3.6 GiB" 下载并运行模型权重:
# 也可使用 ollama run qwen3:4b 直接运行
ollama pull qwen3:4b查看下载的模型权重:
[skyzcyou@arch-honor ~]$ ollama list
NAME ID SIZE MODIFIED
qwen3:4B a383baf4993b 2.6 GB About a minute ago运行并简单测试:
[skyzcyou@arch-honor ~]$ ollama run qwen3:4B
>>> How many times does the letter 'r' appear in the word 'strawberry'?
<think>
Okay, let's see. The user is asking how many times the letter 'r' appears in the word 'strawberry'. Hmm, I need to count the number of 'r's in that word. First, I should
probably write out the word and check each letter one by one.
So, the word is 'strawberry'. Let me spell it out: S-T-R-A-W-B-E-R-R-Y. Wait, let me make sure I have that right. Let me break it down:
S, T, R, A, W, B, E, R, R, Y. So that's 10 letters in total. Now, I need to count how many times 'r' appears. Let's go through each letter:
1. S – not R
2. T – not R
3. R – that's one R
4. A – not R
5. W – not R
6. B – not R
7. E – not R
8. R – that's two R's
9. R – that's three R's
10. Y – not R
So, in total, there are three 'r's. Wait, but let me double-check. Maybe I miscounted. Let me write the word again with positions:
Position 1: S
Position 2: T
Position 3: R
Position 4: A
Position 5: W
Position 6: B
Position 7: E
Position 8: R
Position 9: R
Position 1'th: Y
Yes, that's correct. So positions 3, 8, and 9 are R's. So three times. But wait, sometimes people might confuse the spelling. Let me check the spelling of "strawberry"
again. S-T-R-A-W-B-E-R-R-Y. Yes, that's right. The 'r' is in the third letter, then after the 'e', there are two more 'r's. So three in total. Therefore, the answer
should be 3.
</think>
The letter 'r' appears **3 times** in the word "strawberry".
**Step-by-Step Explanation:**
1. Write out the word: **S-T-R-A-W-B-E-R-R-Y**.
2. Identify each letter and count the 'r's:
- Position 3: **R**
- Position 8: **R**
- Position 9: **R**
3. Total count: **3**.
**Answer:** 3.
>>> Send a message (/? for help)可以看到测试成功,并且默认的思考流程,最终答案也正确。
【附加方案】离线下载模型权重并运行
除了使用 ollama pull/run 进行在线下载之外,ollama 也支持运行离线下载的自定义模型(只支持 GGUG 格式)。可以在 HuggingFace 或 ModelScope 社区中进行下载:
Qwen3-4B-GGUF:Qwen3-4B-GGUF
每个GGUF量化的权重都包含多个版本:
下载 Q4_K_M 量化版本的 GGUF 权重进行调用,下载方式:模型的下载。
下载完成后,查看下载的模型权重文件:
[skyzcyou@arch-honor Qwen3-Test]$ ls -lh
total 2.4G
-rw-r--r-- 1 skyzcyou skyzcyou 2.4G Apr 30 14:33 Qwen3-4B-Q4_K_M.gguf创建 ModelFile 文件,用于注册模型到 Ollama,文件内容如下:
FROM ./Qwen3-4B-Q4_K_M.gguf将该自定义模型加入 Ollama 本地模型列表:
[skyzcyou@arch-honor Qwen3-Test]$ ollama create Qwen3-4B-Q4_K_M -f ModelFile
gathering model components
copying file sha256:d0c2ac093a77c402f2ddc23a64f68b7c70cfef151899b33e3a6066247104ced3 100%
parsing GGUF
using existing layer sha256:d0c2ac093a77c402f2ddc23a64f68b7c70cfef151899b33e3a6066247104ced3
writing manifest
success
查看该模型:
[skyzcyou@arch-honor Qwen3-Test]$ ollama list
NAME ID SIZE MODIFIED
Qwen3-4B-Q4_K_M:latest 0c6f86d24508 2.5 GB 53 seconds ago
qwen3:4B a383baf4993b 2.6 GB 2 hours ago 这便成功载入自定义模型到 Ollama,运行方法为 ollama run 模型名称。
llama.cpp
Qwen3系列模型目前也可以使用 llama.cpp 进行纯CPU推理或者CPU+GPU混合推理。
#TODO
transformer原生库调用流程
#TODO
5 . 昇腾相关
5.1 基础概念
大模型的生命周期通常涵盖从数据准备到部署迭代的全流程,昇腾社区的不同工具在不同阶段发挥作用。
大模型的典型生命周期阶段如下表:
华为昇腾生态简单概览:
以下是几个重要组件的说明:
CANN(异构计算架构):CANN(Compute Architecture for Neural Networks)是华为针对AI场景推出的异构计算架构,向上支持多种AI框架,包括MindSpore、PyTorch、TensorFlow等,向下服务AI处理器与编程,发挥承上启下的关键作用,是提升昇腾AI处理器计算效率的关键平台。同时针对多样化应用场景,提供多层次编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。
昇思MindSpore(全场景AI框架):集核心框架、模型、开发套件等于一体的全场景AI框架。
MindSpeed(训练加速框架):专为昇腾硬件设计的大模型训练加速库,支持从数据预处理到模型训练的全流程。
MindIE(推理引擎):面向昇腾硬件的高性能推理引擎,适用于模型部署和服务化场景。是基于昇腾硬件的运行加速、调试调优、快速迁移部署的高性能AI推理引擎,分层开放满足各类需求,统一接口使能极简开发,沉淀能力构筑极致性能。
对于 Qwen3,DeepSeek 这种开源模型即可使用 MindSpeed 进行训练微调,MindIE进行推理部署。
相关模型权重文件可在:MindIE - Modelers 魔乐社区 找到。
#TODO 在昇腾平台上利用相关工具链实操,暂无相关环境
5.2 相关文章
在阿里千问3开源数小时后,华为官方宣布昇腾支持千问3全系列模型部署,开发者在MindSpeed和MindIE中开箱即用,实现 Qwen3 的0day适配。
加载镜像: 前往昇腾社区/开发资源下载适配本模型的镜像包mindie:2.0.T17.B010-800I-A2-py3.11-openeuler24.03-lts-aarch64.tar.gz 完成加载镜像后,使用
docker images命令确认查找具体镜像名称与标签。约束条件: 当前支持TP=1/2/4/8推理
新建容器: 目前提供的MindIE镜像预置了Qwen3-4B-Base模型推理脚本,无需再额外下载魔乐仓库承载的模型适配代码,直接新建容器即可。
Qwen3 正式发布!模力方舟首发上线体验,昇腾算力全面适配 - OSCHINA - 中文开源技术交流社区
为释放
Qwen3的强大性能,模力方舟基于昇腾最新发布的vLLM Ascend v0.8.4rc2进行适配。新版vLLM Ascend率先实现Ascend W8A8量化、DeepSeek并行机制适配,并启用PyTorch 2.5.1及Torch.compile图模式特性,在推理性能、兼容性与开发体验上全面升级,为大模型部署提供了更高效、更专业的基础能力。
One more thing - 2025.04.30 update
Qwen2.5-Omni 是Qwen系列中全新的旗舰级端到端多模态大模型,专为全面的多模式感知设计,无缝处理包括文本、图像、音频和视频在内的各种输入,同时支持流式的文本生成和自然语音合成输出
继 Qwen3 正式发布后,Qwen 团队又发布了一个新模型 Qwen2.5-Omni-3B。
- 与 Qwen2.5-Omni-7B 模型相比,3B 版本在长上下文序列处理(约 25k 个 token)中实现了令人瞩目的 50%+的 VRAM 消耗降低,同时在典型的 24GB 消费级 GPU 上支持扩展的 30 秒音视频交互。
- 保留了 7B 模型的 90%+的多模态理解能力,自然语音输出的准确性和稳定性与 7B 版本相当。
Qwen/Qwen2.5-Omni-3B - huggingface.co
Refer
官方材料:
一分钟!看懂Qwen3家族_哔哩哔哩_bilibili-官方视频
官方平台:
通义AI助手平台:https://www.tongyi.com/
官方ChatUI:https://chat.qwen.ai/
昇腾社区相关:
网络资料:
Qwen3 Release and Overview: How it is Different From Other LLM Models
Qwen 3 offers a case study in how to effectively release a model
Qwen-3深度解析!硬件配置、原生MCP功能介绍、模型选择详解!仅需1/3硬件成本,性能超越DeepSeek-R1!_哔哩哔哩_bilibili-九天Hector